In 2019 I created a Twitter bot named @Emojify1:
It was a simple bot that, whenever someone @ mentioned it with a photo, would respond with that same photo but emojified.
I was quite happy with the results; however, there were two major issues:
- It was really slow, taking ~40 seconds to emojify as 1024x1024 image.
- I would get stack overflow & OOM errors when the input image resolution was over ~2000px.
So, I made a fun decision back then: I'll revisit the project once I have more knowledge and experience.
Now, the time has come.
Background
I started coding when I was 9, and my approach was solely hands-on; I never engaged in any formal learning (books, courses, etc.). This created a few obvious gaps in my knowledge, most notably:
- A complete lack of understanding of data structures.
- No deep knowledge of computers (at a lower level).
I'd argue that the key to computer performance lies in deeply understanding both. Naturally, then, 2019's Emojify lacked both, which lead to poor performance.
Thankfully, from 2019 to 2024, I have:
- Started computer science;
- Worked professionally as a software engineer for 03 years;
- Read a bunch of books about computers: Processor Microarchitecture: An Implementation Perspective, But How Do It Know?, A Primer on Memory Consistency and Cache Coherence and others;
- Finished a bunch of MIT OpenCourseWare's courses: Introduction To Algorithms, Design And Analysis Of Algorithms, Performance Engineering Of Software Systems and others;
Which is why I'm redoing Emojify now; I've grown in areas that I feel will make a difference for the problems Emojify had.
2024's Emojify
2019's @Emojify1 was banned when X changed its bot policies, so 2024's Emojify isn't an X bot—it's a WASM package hosted on my personal website here.
It's written in Rust because: a) I wanted a non-GC language; b) I was looking for an excuse to learn a bit of Rust.
The goal was not to make it as fast as possible, but rather to make it fast enough. What's "fast enough" or not is, naturally, subject to my own personal interpretation.
The algorithm
I created 2019's Emojify algorithm from scratch. It's pretty simple:
- For each emoji, I pre-computed its average RGB value:
{ "emoji_file": "10.png", "avg": [ 229, 75, 75 ] }
* - At runtime, I searched for the emoji that had a
avgwith the least delta from a given pixel in the input image.
There are definitely algorithms that would produce a higher fidelity output image, but this was the first thing that came to my mind in 2019 and surprisingly it worked well. For 2024's Emojify, I'll use the same base algorithm.
The plan
The plan was to recreate 2019's Emojify code 1:1 and then:
- Profile & benchmark;
- Optimize the biggest bottlneck;
- Repeat until it's fast enough.
Ok, onto coding the initial 1:1 version of Emojify in Rust! It will definitely be faster.
It was... slower. Taking 55 seconds to emojify an image where the JS (2019's) version took 44 seconds.
This was weird — how could the exact same code be slower in Rust than in Javascript?
I instinctively thought, "Wow, ok... I should probably optimize the emoji search step. I'm just doing a simple full array search. I know KDTree can do multidimensional searches in O(logn), so I should use that..."
But I decided to stick to the plan of profiling to identify the biggest bottleneck in order to ensure I was always doing the most impactful work possible.
From 55 seconds to 12 seconds
Upon profiling it as a flamegraph, I saw something unexpected:

libsystem_platform.dylib_platform_memmove (1951 samples, 73.67%) was the biggest bottleneck. That was strange because I supposedly wasn't performing that many memory copying operations.
Then I took a closer look at this function:
fn single_emojify(img: &PhotonImage, pos: (usize, usize)) {
// Gets the RGB value of the input image at a given position (x, y)
let rgb = pixel_value(img.get_raw_pixels(), pos);
// Find the emoji with the least delta
let emoji = find_emoji(rgb);
// Adds the emoji to the output image at the given position
add_emoji(img, emoji, pos);
}
single_emojify() is called for every emoji in the output image and its purpose is to add an emoji in a given pos. In order to accomplish that, it first needs to get the RGB value of the given pos. And the problems lies on that:
img.get_raw_pixels() is a photon_rs function that returns the raw pixel values of the image. When first coding, I didn't notice but under-the-hood its actually copying the internal pixel values and allocating a new Vec<u8> array in memory.
That's what was causing the many memmove. Fixing this was trivial and it reduced the time from 55 seconds to 12 seconds!
Yeah, turns out it wasn't an exact 1:1 copy... Now it was and we can see the difference between Rust and JS: Rust takes 12 seconds while JS takes 44 seconds.
After fixing the unnecessary memory allocations, I thought:
"Ok! Now it's time to optimize the algorithm and use fancy data structures!" — Me
Obviously, I was... wrong again. The next optimization was simply writing a more efficient overlay function.
From 12 seconds to 4 seconds
For a given pos (x & y coordinates), we need to find the emoji with the lowest avg delta from the RGB value for that position, but after finding it, how do we actually add the best emoji to the output image?
I was using photon_rs's watermark() function, which takes two images and overlays one image over another in a given position.
However, during the second round of profiling, watermark() proved to be the biggest bottleneck. This left me with two options: i) look into the internals of photon_rs and hope to optimize it; ii) create my own overlay function suited for my specific use case. I opted for the latter as it seemed manageable.
For the first version of overlay(), I coded the most naive, brute-force approach I could: get the RGB value from overlay_img and overwrite it in overlayed_img. I was sure this would perform worse than photon_rs's watermark() and that I would need to get clever with memory locality and SIMD with techniques like tiling and vectorization.
Surprisingly, when I benchmarked it, the results were excellent! Going from 12 seconds to 4 seconds.
From 4 seconds to 2.5 seconds
Profiling again, the naive overlay() was far from being the bottleneck—it was two functions from photon_rs: resize() and open_image().
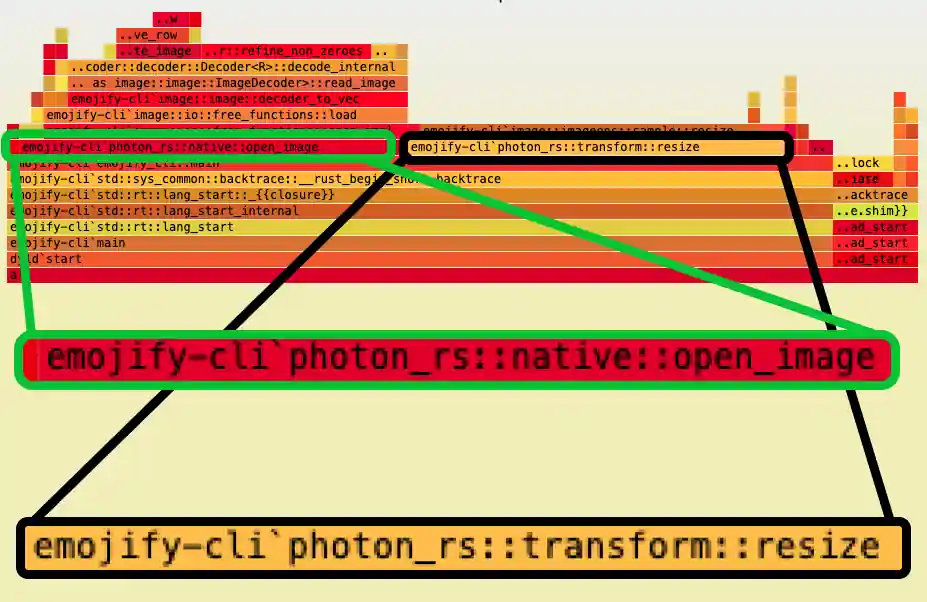
open_image()
As the name suggests, this function takes a path and returns a PhotonImage. It accounted for about 42% of the runtime because Emojify needs to open lots of images. It has to open the input image and some subset of the ~2k emojis.
I was lazily opening the emoji images, which is good because instead of needing to load all 2k emojis, we end up loading only about 100.
So, for each selected emoji, Emojify needs to load it from disk.
resize()
As the name suggests, again, resize() is a function that takes an image and a 'resolution: (width, height)' and returns a new image resized to those dimensions.
We need to use resize() because the emoji images are 64x64 px, but for most input images, we need smaller resolution emojis. Otherwise, the output image would have gigantic emojis, e.g.:

For each selected emoji, Emojify first resizes it to an NxN dimension—where N remains constant during the emojification of a given image.
Making both faster
The problem arises from the fact if an emoji is selected N times, we're loading it from disk N times & then resizing it N times. This is unecessary work that we can easily optimize: load from disk & resize it only the first time it is selected.
By applying memoization, the total runtime goes from 4 seconds to 2.5 seconds.
2.5 seconds to 1.2 seconds
The output image can (and probably will) have a different resolution than the output image. To create an emojified image, I initially resized the input image to create a larger canvas for the output, onto which I would overlay emojis. This approach involved resizing the original (input) image to the predefined output resolution before beginning the emojification process, where emojis are added to the upsized image.
However, this method of resizing the input image was unnecessary work — I knew that from the get-go. The reason I was doing it was for convenience only.
Eliminating the step of resozomg the input image removed the current bottleneck, leading to a reduction in processing time — from 2.5 seconds to 1.2 seconds!
1.2 seconds to 450ms
As I've mentioned multiple times previously, I always thought that the best optimization would be using a fancy data structure, and it never actually was... until now!
Our biggest bottleneck now is in find_emoji(), which is a function that takes in input_img & pos: (x: usize, y: usize) and finds the best emoji for the given image in the given pos.
Currently, this function searches an array that contains all the ~2k emojis, and for each, it calculates the delta of the emoji's average RGB value versus the RGB value of the given image at pos.
From previous projects, I knew I could use a K-d tree — which is somewhat like a binary search tree but n-dimensional. The cool thing about them is that, once created, they can search in O(log n) on average.
With this change, we went from 1.2 seconds to 450ms!
When I reached this speed, I felt it'd be a good time to port it to WASM since:
- This was my first real Rust project. I wanted to feel comfortable with the language before trying WASM, and by this time, I finally felt comfortable with it;
- The other optimizations we could still do would rely on things that would behave differently in the browser versus natively—like memory locality, SIMD, multithreading, etc.
WASM
Initially, when ported to WebAssembly, the runtime went from 450ms to... 4.07 seconds.
4 seconds it completely not acceptable. So what did I do? Exactly the same as before:
- Profile the app;
- Spot the biggest bottleneck;
- Apply the naive optimization to it.
WASM's 4.07 seconds to 354ms
photon_rs's resize() was the problem, but it is a native function from the image library I was using... How do we fix it? Similarly, as we did with watermark(): we create our own resize()!
I won't go in details into Emojify's custom resize() because is out of scope for this post. I just want to clarify that I did not create a 92% faster resize() than photon_rs.
What I did was make reasonable trade-offs given my use case. For instance, my resize() can only scale down, it completely disregards the alpha channel, and its accuracy is terrible, however, that doesn't matter because for my use case it's more than enough.
WASM's from 354ms to 32ms
WASM and JS don't share the same memory space, and by default, when JS calls a WASM function passing N parameters, all N parameters need to be allocated in WASM's memory (and when a WASM function returns, it also needs to be allocated in JS's memory).
The catch here is that JS can access WASM's memory. Therefore, instead of JS passing an input image (which is just a huge array of unsigned int), it writes to WASM's memory and then passes a pointer to that as the parameter. The same goes for when a WASM function returns a value.
The idea was modify the Rust's emojify() function to take a pointer to the input image and return a pointer to the emojified output image. Pretty simple.
Doing this reduced the runtime from 354ms to 32ms!
32ms is a time that I'm feel happy with — although I must say that there's an appeal in going under 10ms — so I'll leave at that.
Conclusion
The number one takeway from doing Emojify five years later is: you cannot improve that which you don't measure. So, profile! Profile! And profile again!
Our intuitive sense is often wrong and cannot be trusted. If you have data, use it in order to decide what to optimize.
Oh, and you can try Emojify 2024 version here.