I've always found the idea of self-play in reinforcement learning one of the most beautiful ideas in the world — creating systems that truly learn entirely on their own is Art to me.
You create a world for a system to live in, provide it with enough compute, and let it play against itself... Suddenly, you have an AI that performs at a superhuman level in that world. Art.
While the GPT-3 announcement and the ChatGPT launch were defining AI moments for many, my defining moment in AI occurred years earlier with OpenAI Five's victory over the world champions in Dota 2.
It was specially impressive to me because I was a Dota player. I knew how fucking hard Dota is; far harder than chess or Go:
- Long time horizons: Dota 2 games run at 30 frames per second for approximately 45 minutes. OpenAI Five selects an action every fourth frame, yielding approximately 20,000 steps per episode. By comparison, chess usually lasts 80 moves, Go 150 moves.
- Partially-observed state: Each team in the game can only see the portion of the game state near their units and buildings; the rest of the map is hidden. Strong play requires making inferences based on incomplete data, and modeling the opponent's behavior.
- High-dimensional action and observation spaces: [For pratical reasons] OpenAI Five on an average timestep chooses among 8,000 to 80,000 actions (depending on hero). For comparison Chess requires 1,000 values per observation and Go ~6,000.
Excerpt from OpenAI Five paper.
Having said that, I had never explored the field of RL — that is, until I got COVID last week and was issued a medical certificate for three days off work: I decided it'd be a cool challenge to learn as much as possible during those three days while I was sick. and this blog post is precisely about that experience.
The plan
With only three days at my disposal, the plan was:
- Day 01: Read Deep Reinforcement Learning in Action.
- Day 02: Start training my own RL model to solve PONG.
- Day 03: Train through self-play a RL model to solve PONG.
The reality
Day 01
Deep Reinforcement Learning in Action has 11 chapters, and each one introduces a different RL algorithm/model and asks the reader to implement it. This makes it a great learning resource, but naturally, it also means it's a bit slower to read than expected.
While reading each chapter, I had a bunch of ideas that I wanted to try out, such as using a LLM to bootstrap; this was great because I learned a ton, but it made apparent progress slower. Hence, at the end of day one, I was behind schedule at chapter 7.
Day 02
Since I needed to catch up, I decided to wake up at 04:30 AM and start reading as soon as I got out of bed, which allowed me to finish the book by noon.
After finishing the book, I immediatly started to implement PONG. I decided to use A2C to train the model — why A2C? Because I liked PGMs! They're simply prettier than other methods such as DQNs (which, by the way, are extremely ugly).
Before implementing A2C, though, I wanted to set a baseline, and for that, I chose REINFORCE — which is kind of its predecessor.
Since I didn't have much experience with CNNs (convolutional neural networks), I decided to simply use a dense model that takes the last four 80x80 frames in grayscale.
Eventually, with all the code written, it was time to let it train... and the results were bad. It simply was not learning.
That was a surprise to me. All the models from the book were similar, and I had no problem training them. Why was I having problems now with a game as simple as PONG?
Well, it was a combination of different factors:
- Finding the right hyperparemeters was though. In the book the author give aways what values to set the hyperparemeters.
- ONG was a harder problem than I expected (and also harder than the book's examples) mostly due to the sparsity of the rewards (meaning you have to take a bunch of actions before any rewards occur) since they only happen when someone scores. In the book, the problems we solved had continuous rewards, e.g., cartpole.
- Bugs in the implementation.
- Not doing "small things" correctly: no frameskipping,
preprocessing_frame()function had some minor issues in the first few frames of the game and also the last few frames, etc. - Not training for enough time.
Naturally, it wasn't trivial to discover and fix all the above. So, at the end of day 02, I was stuck trying a number of different things with nothing really working. I felt I had no choice but to pull an all-nighter (which, by the way, is something I enjoy doing from time to time).
Day 03
Day 03 started at midnight and lasted until 9 PM. Honestly, it just consisted of me trying a lot of different things. The things that proved beneficial were:
- Started using Weights & Biases (great product, by the way) to store and analyze the runs. This helped tremendously in finding the right hyperparameters.
- Parallelized the training to run multiple environments simultaneously, decreasing the training time linearly. This allowed me to iterate far faster and also conduct longer training runs.
- Configured a debugger that works in Jupyter notebooks which I can't imagine how I would fix the implementation bugs without.
- Just let the model train for way longer.
By late afternoon, the model started to show signs of learning—really slow and unstable. Nonetheless, it was learning! I was so pumped since now it was only a question of tuning a few things and letting it train longer.
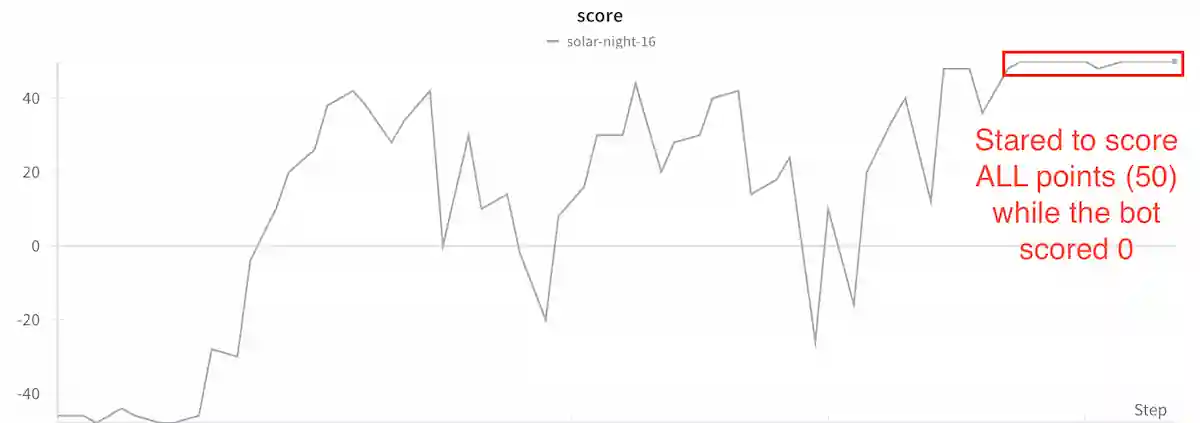
Finally, at around 7 PM, I started what would be the final training run, which lasted for 15k episodes. By around 12k episodes, we had absolute success; it was literally not letting the bot it was playing against score a single point.
Here's a video of the model playing against the hardest bot:
On memorization versus generalization
You can see that the model learned a strategy that humans simply cannot execute, i.e., always hit the ball in a particular way such that it bounces at a specific point at the top and goes to a specific point at the bottom, making the bot it's playing against miss.
This may seem like a cheesy strategy and it kind of is, since when the model plays against a human it simply tries to do that move and it does not work. Is this a problem? Well, if your goal is to train a PONG model that beats humans, then yes. However, my goal was to simply beat the hardest bot.
How would one tackle this problem? The problem arises because Atari games are entirely deterministic; agents can achieve state-of-the-art performance by simply memorizing an optimal sequence of actions while completely ignoring observations from the environment. To avoid this, one can add a bit of stochasticity to the environments, which can be done in a number of different ways.
Alternatively, self-play would also address this.
Outcome
Though I was not able to complete the original plan (doing self-play and A2C), I was super happy with what I was able to achieve in three days. I learned a ton.
Conclusions
- Machine learning and RL are super hard. During the three days, I've gained even more respect and admiration for AI researchers.
- RL models fail silently makes things much slower and is a huge problem.
- Let the model train longer — it really wants to learn! Just give it enough compute.
- DQNs are ugly and I intuitively feel they'll become an artifact from the past that goes against The bitter lesson. PGMs, on the other hand, feel like the opposite.
- Doing and learning RL is so so so much fun. I'm eager to continue learning and tackling harder problems.